Mitigating Internet Censorship and Privacy Issues with IPFS and WASM
The purpose of this article is to propose a unique combination of modern web technologies to address the increasing problems of website censorship and privacy breaches.
We will explore how Tantivy, WebAssembly (WASM), and the InterPlanetary File System (IPFS) can be used to create web applications with embedded databases that can be delivered and run directly in a user’s browser without relying on a remote server.
Let’s start from the model that is a root of all our issues.
Good Old Client-Server and Its Drawbacks
In 2023, the client-server architecture is still the most widely used model on the internet. Despite ongoing efforts to revise and improve the model, it continues to be used with all its advantages and disadvantages.
In a client-server model, the server provides services to clients and may have extensive computing capacities and record a history of interactions with all clients.
For example, a user may create an account and a server records this account and allows the user to log in later. Another example is a search engine that collects search logs to improve its search quality in the future.
These two traits are very beneficial and allow to create very complicated and functional web services such as social networks, search engines, mobile offices, messengers and many others. However, the client-server model has three major drawbacks that may render its usage unsuitable in particular conditions.
Firstly, the interaction between a user and a remote server is carried out through a hostile environment, such as wires controlled by state agencies or telecom companies. Encryption can protect the content of messages, but the fact of interaction is still exposed and communication can be cut by those who have physical access to wires or political power over telecom companies.
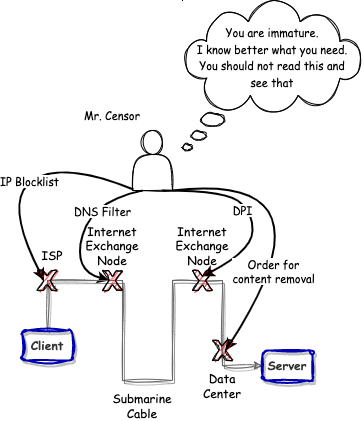
Secondly, websites often log your requests, which fundamentally leaks your privacy because the history of your interactions with the site is no longer exclusively yours. Every time you send a request to a server, you compromise your privacy.
Even if the connection is secure, the company owning this server may use your data for its own purposes or accidentally leak your data to a third party.

While laws like GDPR, CCPA and others aim to protect users from uncontrolled tracking, they may paradoxically lead to a greater inequality. Most of the society does not have access to each other’s private data, but hackers and state agencies do. The massive leaks of 2022 show that in practice, everyone has access to your personal data but not you. The only available way to keep privacy is through technology.
Thirdly, the server may go offline, and there is nothing you can do about it. Just imagine waking up one day without Google.
What if the client-server model were revised for increased resilience against censorship and privacy concerns? This article explores a refreshed approach that brings websites closer to users.
It’s important to note that this approach does have its limitations and to manage expectations, we’ll only focus on web applications that:
- Don’t rely on confidential algorithms/data or at least may function properly without them
- Don’t require private data from other users except yours to be locally functional
- Don’t require a lot of computational capacity and must be launchable by typical consumer hardware
In essence, this approach involves creating apps that generate and store private data locally and download only a small amount of public data from the network. There will be no servers executing code, only ones that share files with the user.
I’d like to underline the 3rd point which limits computational capacity but not an amount of data that may have any size.
Proposed Solution
A typical website consists of three components:
- A web interface that the user interacts with
- An API that performs useful actions
- A database that stores valuable information
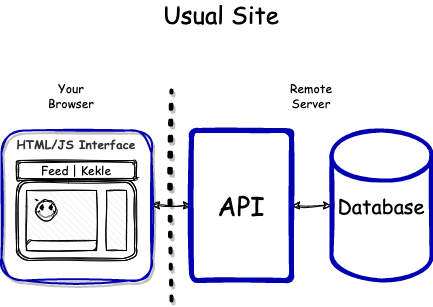
What if we package all three components into a single web bundle that runs in a user’s browser?
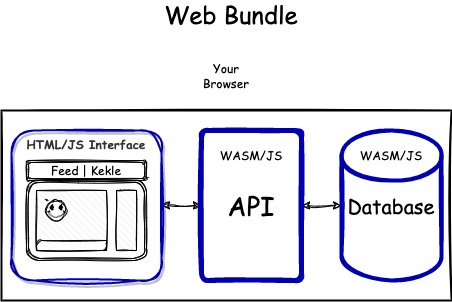
Packaging involves making all components executable within browsers, and delivering these components into browsers. Let’s examine three seemingly unrelated technologies that can help us achieve these goals.
Tantivy
The data required for your website can be stored in different forms such as relational databases, key-value storages, or inverted indices. Each form provides unique capabilities; for example, relational databases are suitable for recording items such as users or actions, key-value storages can be used for counting or caching items, and inverted indices are ideal for text searches.
Here we are going to consider Tantivy search library, published by a former Google employee in 2017. Tantivy’s architecture is similar to Lucene, but it is faster and has a smaller code base. Its architecture is described in detail in other article, here I will only mention the most important properties of Tantivy for our case:
- The performance of the library is faster than Lucene/ES
- Data files generated by Tantivy are immutable
- Every search request is local and requires reading only a small amount of data from disk
By data immutability I mean the following: the data is saved in a set of files called a segment after, and files are not modified after commit. The next commit saves a new batch of data in new files, and the fact of deletion of a row is stored as a bit in a bit mask next to the existing segment. Data updates are implemented as delete and insert operations, and therefore the segment itself remains unchanged during any operations with data. Data immutability is essential in a network environment because aggressive caching of everything becomes possible.
Poor locality is the main problem that prevents running an arbitrary database on top of a p2p system or network file system. Random reads overload the network and simply exhaust it with any significant load. By combining certain approaches, Tantivy was able to achieve high locality for all components of the search index.
In practice, locality means that not all index files need to be downloaded into the browser for executing search queries locally, but only a portion of the relevant files.
WASM
WASM is a byte-code format that can be executed in web browsers. It was first introduced in 2015 and has since undergone several years of development. Despite initial setbacks caused by the Meltdown and Spectre vulnerabilities, interest in WASM has been growing in recent years. The main advantage of WASM is that programs compiled in this format can run in a web environment, namely in browsers. Toolchains for compiling into WASM are available for programming languages such as C++ and Rust what makes the development much easier.
By the end of 2022, I managed to compile Summa into a single 5MB binary and create the summa-wasm library, which also provides JavaScript bindings to Summa. This means that all the search capabilities of Summa are now available in the browser. Additionally, a networking layer was written to substitute range file reads with range network requests. As a result, every search request that previously required 5-10 32KB disk reads may be translated into 5-10 network requests that download 32KB of data.
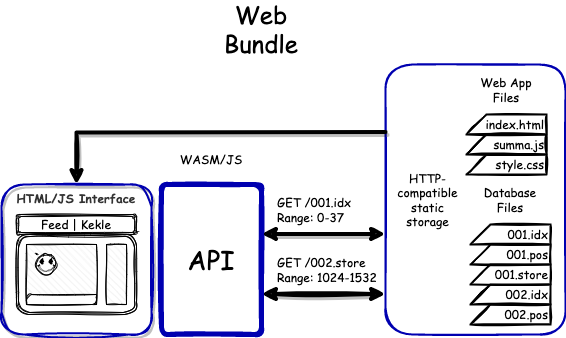
Furthermore, the summa-wasm library implements aggressive caching policies that dramatically reduce the number of bytes needed to be downloaded for executing queries.
IPFS
At the moment, we have a search engine that functions within a browser and retrieves search indices data files through HTTP requests when executing a search query. The missing piece that would take us into the realm of P2P is IPFS.
IPFS is a well-established technology that was introduced in 2013. Simply put, it operates similarly to BitTorrent, enabling you to download files from “peers” using file identifiers. There is no central authority for file hosting, so as long as you have good connectivity with the IPFS peer network and peers are seeding the required files, you can access any files you need.
The IPFS software also provides crucial components, such as the HTTP IPFS Gateway, which allows you to load files from IPFS using standard HTTP protocol. The gateway opens browsers to IPFS and hence bridges the software executing within the browser with IPFS.
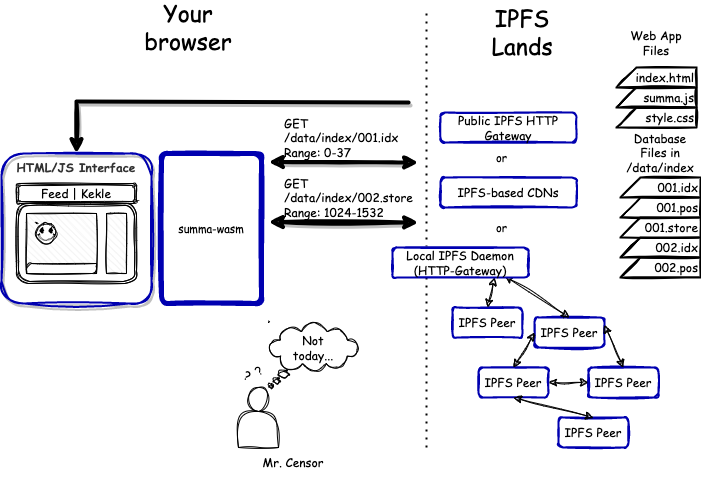
The general idea is straightforward: we put web applications and data files in a single IPFS directory and distribute the directory through IPFS. The HTTP IPFS Gateway allows us to access all files of the bundle through the HTTP protocol, including the index.html that will be rendered by browsers as usual HTML file, serving us as the entry point to our web application.
Summa
Summa is a full-text search engine that combines three technologies from above to help you in creation web bundles deliverable through IPFS.
A little over a year ago, I started developing the Summa server, which initially added
- a GRPC API for search and indexing to Tantivy
- the ability to index from Kafka topics
- the fasteval2 language for describing ranking functions
- and some extra search functions
At the same time Summa has been made compatible with WASM. All Summa parts, including the network layer for loading index parts with HTTP requests, have been shaped into summa-wasm module which now allows you to execute search queries over Summa indices directly in browser.
Why It Is So Special?
With the integration of summa-wasm into your web application, you will have the ability to access data by key and perform full-text search queries on large datasets, making it easier to build a very important class of web applications: uncensorable search engines.
Search engines encompass not only classical search but also news feeds and encyclopedias, all of which have suffered greatly from censorship in recent years.
If your web application requires a different type of database, you have the option of using Summa as an alternative or compiling the necessary databases into WASM, although this may require a significant effort.
Regardless of your choice, it is crucial to re-architect your application to be more open. The more private parts and centralized server APIs your application has, the higher the risk of censorship through attacks on the servers or their infrastructure.
Now let’s delve into using Summa to build an uncensorable web.
Practice
Create a search index on the server
Basic example on how to create a search index with Summa you may find in Quick-start guide. The process is not different from any familiar to you process of database population with data.
Create web-interface that uses this search index
At this point you must create a web-application, something like a PWA that makes all operations locally and may interact with Summa database through summa-wasm bindings and supposing that index data files lay somewhere near.
Summa provides an example of news feed site that may be used as a base for your application.
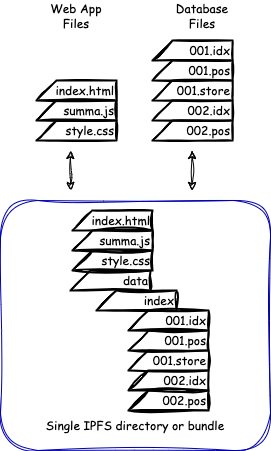
Bundle your web-site
Now we should bundle all together.
# Endpoint of Summa GRPC API
summa_api=0.0.0.0:8082
# Here should be your index name
index_name=ipfs_index_name
# Path to compiled web application with index.html
web_app_path=web/dist
web_cid=$(ipfs add --pin -Q -r --hash=blake3 $web_app_path)
data_cid=$(ipfs add --pin -Q -r --hash=blake3 --nocopy data/bin/$index_name)
ipfs files cp /ipfs/"web_cid" /summa-web
ipfs files cp -p /ipfs/$data_cid /summa-web/data/$index_name
ipfs files stat --hash /summa-web
Use!
Try to open your site at local or public IPFS gateway. You may use even Summa for these purposes as it implements HTTP IPFS specification and launches gateway on 8080 port.
Optionally set IPNS or DNS name
IPFS supports DNSLink specification for aliasing IPFS CIDs. You may set DNS records to point to your web bundle, and it will be loaded by browsers with installed IPFS Companion extension. Such browsers as Brave even contains embedded IPFS daemon that eliminates all needs to configure IPFS manually.
Afterwards, you will have a website with an embedded database that may be accessed through HTTP IPFS Gateway. Updating the search database and the website itself will require some effort, but it is well-supported due to two factors: index immutability and IPFS caching. All updates to the database will be stored in a separate segment that will be distributed as part of a new bundle. Meanwhile, the IPFS daemon will not redownload existing parts of the index, meaning only updates will be downloaded.
Conclusion
Distributing search indices in Tantivy format provides several distinct and beneficial properties. As previously mentioned, Tantivy boasts impressive locality, which means that only a small portion of the remote data is needed to be downloaded to execute a local search query.
By requesting these portions of data through IPFS, you also become a seeder of these chunks, distributing them further. In its turn, portions of the index relevant to more frequent queries will be seeded more often and thus, more actively distributed.
This characteristic makes the entire system more self-balancing.
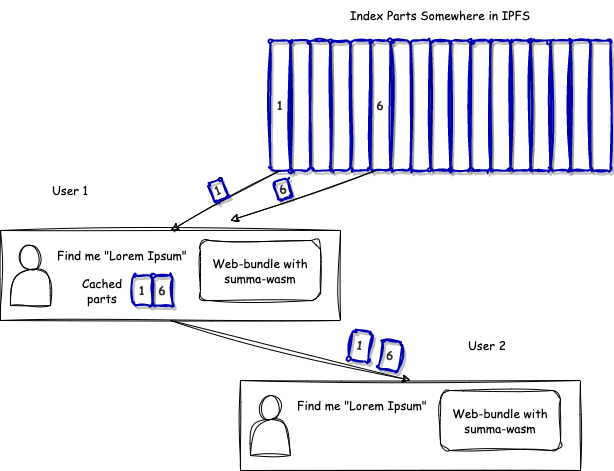
The chunking and caching in IPFS also offer advantages, as even after updates, most of the search index remains intact and thus, there is no need to redownload these files. Different approaches to index layout can be used to further reduce the amount of data that needs to be transferred.
For example, in a news feed site, you could sort all your news items by their time and create new chunks of data every hour or day. Old parts of the search index may not even be requested most of the time, as people typically only read the latest news.
Distributing data via IPFS offers benefits for privacy. Although it is still theoretically possible to determine which pieces of data you have gathered, it is practically impossible and yields very little information to an observer. When all data pieces are downloaded locally, your web bundle becomes localized, and as a result, your interactions with it do not generate any network activity. With no activity, there is no chance of being tracked.
Also, no surprise that services built on top of IPFS are better suited for interplanetary communication than client-server services, as data transmission is more reliable and less sensitive to delays compared to command transmission. Furthermore, the transmitted chunks of data become available to all local peers on the other planet.